Appearance
基于AI技术制作合同通用条款审查应用
基于AI技术制作合同通用条款审查应用主要是利用大语言模型的生成技术来辅助审查合同或提取合同内容。主要操作步骤有:
第1步:建立工作流,根据需求编排工作流;
第2步:建立工作流应用,根据目标工作流建立工作流应用;
建立工作流
AI平台—>我的工作流—> 新增工作流—>输入工作流名称和描述
工作流编排整体流程图
按以下流程图添加节点,并将节点连接。未连接的节点将无法获取上游节点的字段。
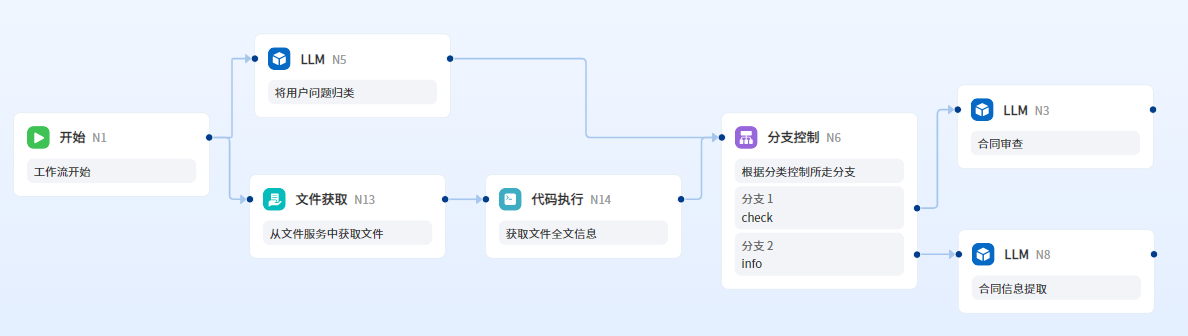
工作流编排步骤简述
- 第1步:增加开始节点,节点用于获取用户指令和需要评审的合同文档;
- 第2步:增加LLM节点,节点用于判断用户指令的意图,确定是进行合同内容的提取,还是进行合同的审查;
- 第3步:增加文件获取节点,节点用于把需要评审的合同文档下载到运行服务的临时目录中;
- 第4步:增加代码执行节点,节点用于解析上传的合同文件并输出合同的内容信息;
- 第5步:增加分支控制节点,节点用于控制需要执行的流程分支,控制是走合同内容的提取分支流程,还是走合同的审查分支流程;
- 第6步:合同审查分支流程增加LLM节点,节点用于进行合同的审查;
- 第7步:合同内容的提取分支流程增加LLM节点,节点用于进行合同内容的提取;
工作流编排步骤详细信息
- 第1步:新增一个开始节点用于获取用户指令和需要评审的合同文档。
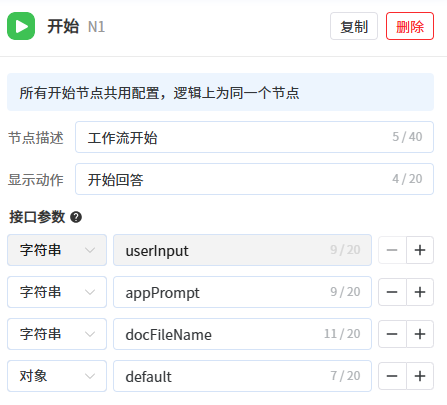
接口参数如下:
userInput:字符串类型,默认存在,接收最新一次用户指令
appPrompt:字符串类型,默认存在,接收工作流应用的人设与回复逻辑
docFileName:字符串类型,需自定义添加参数名,用于接收用户上传文件的路径,上传多份文件时路径通过逗号“,”分隔
default:对象类型,默认隐藏,用于接收用户信息,如用户id、用户名称、第三方用户标识、当前时间、token等 - 第2步:新增一个LLM节点,用于判断用户指令的意图,确定是进行合同内容的提取,还是进行合同的审查,通过编写提示词使其能将用户提问信息归类并输出为“check”或者“info”。
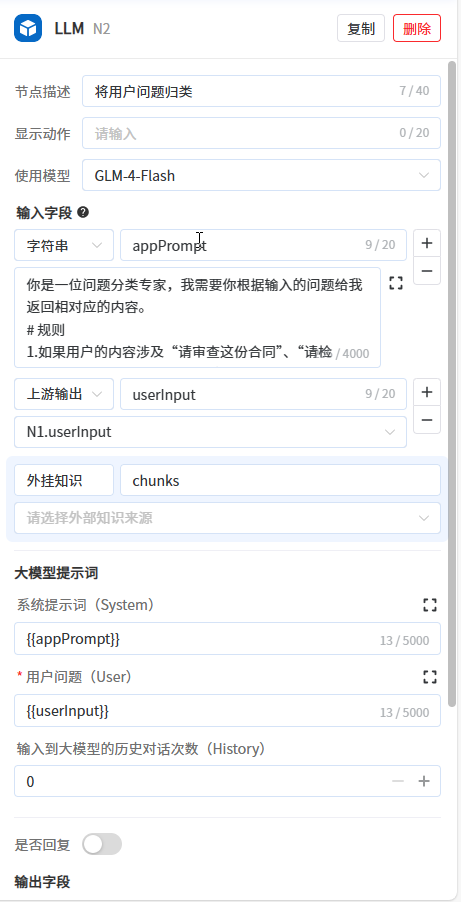
具体步骤:
- 修改输入参数appPrompt类型为字符串,将以下提示词赋值给输入参数appPrompt
text
你是一位问题分类专家,我需要你根据输入的问题给我返回相对应的内容。
# 规则
1.如果用户的内容涉及“请审查这份合同”、“请检查”、“评审”或涉及关于规则的说法,
请给我返回"check"
2.如果用户的内容不涉及第一点的内容,不涉及“请审查这份合同”、“请检查”、“评审”或让你帮忙评审这份合同相类似的说法,
请给我返回"info"
你返回的内容只有"审查"或者"提取",我不需要你返回除此之外任何其他的内容- 关闭是否回复
- 输入参数userInput的值选择开始节点的userInput
- 可设置输入到大模型的历史对话次数
text
0:不带入历史问答
1:带入最新一次完整的问+答
2:带入最新的两次完整的问+答
以此类推- 不同模型对提示词的理解能力不一致,效果不好时可以调整提示词或更换使用模型。
- 第3步:新增文件获取节点,把文件存储服务中的文件下载到运行服务的临时目录中,供后续节点解析合同文件。
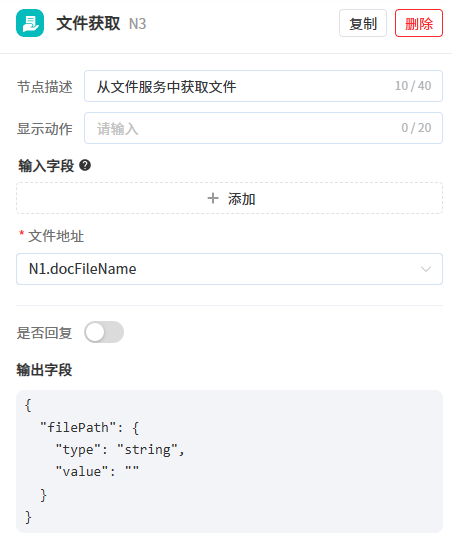
文件地址选择开始节点的docFileName参数,节点将文件名输出到输出参数filePath中,后续代码执行节点可以通过输出的文件名解析上传的合同文件。 - 第4步:新增代码执行节点,用于解析上传的合同文件并输出合同的内容信息。输入为经过文件获取节点处理过的文件名,输出为合同文件的内容信息。
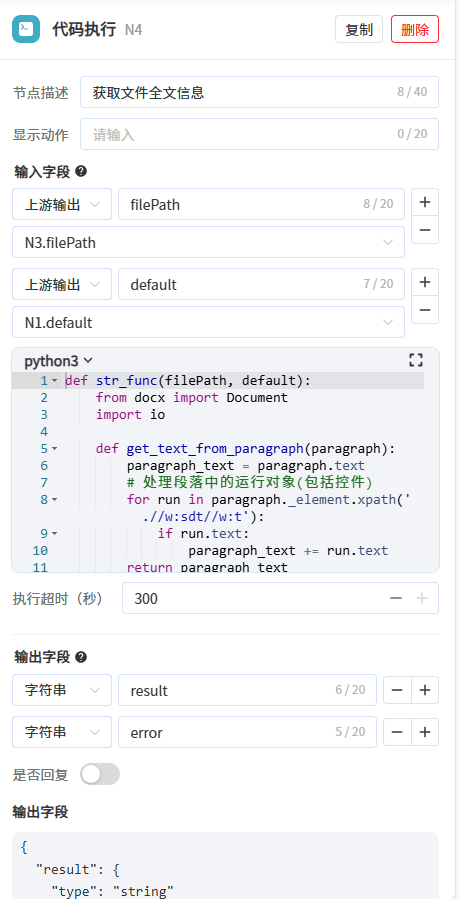
具体步骤:
- 修改输入参数为filePath,类型选择上游输出,值为文件获取节点的输出filePath
- 增加输入参数default,类型选择上游输出,值为开始节点的default
- 将以下代码粘贴到python代码输入框中
python
def str_func(filePath, default):
from docx import Document
import io
def get_text_from_paragraph(paragraph):
paragraph_text = paragraph.text
# 处理段落中的运行对象(包括控件)
for run in paragraph._element.xpath('.//w:sdt//w:t'):
if run.text:
paragraph_text += run.text
return paragraph_text
error_text = ''
text = []
# 区分pdf和docx
if filePath.endswith('.pdf'):
import requests
url = 'http://chat-knowledge-service/api/document/doc2text'
files = {'file': open(filePath, 'rb')}
# 添加请求头
headers = {'Authorization': default['token']}
response = requests.post(url, files=files, headers=headers)
# print(response.json())
if 'data' in response.json() and 'text' in response.json()['data']:
text.append(response.json()['data']['text'])
else:
error_text = "pdf转换失败:" + str(response.json())
text.append('')
else:
doc = Document(filePath)
# 迭代文档中的每个段落
for paragraph in doc.paragraphs:
text.append(get_text_from_paragraph(paragraph))
for table in doc.tables:
text.append("|")
# 表头
headers = []
for cell in table.rows[0].cells:
cell_text = ""
for paragraph in cell.paragraphs:
cell_text += get_text_from_paragraph(paragraph)
headers.append(cell_text)
text.append(" | ".join(headers))
text.append("|" + "---|" * len(headers))
# 表格数据
for row in table.rows[1:]:
row_data = []
for cell in row.cells:
cell_text = ""
for paragraph in cell.paragraphs:
cell_text += get_text_from_paragraph(paragraph)
row_data.append(cell_text)
text.append("| " + " | ".join(row_data) + " |")
return {"result": '\n'.join(text), "error": error_text}- 输出字段增加error
- 第5步:新增分支控制节点,用于控制需要执行的流程分支,控制是走合同内容的提取分支流程,还是走合同的审查分支流程。当第2步的LLM节点返回“check”时走合同审查分支流程,返回“info”时走合同内容提取分支流程。
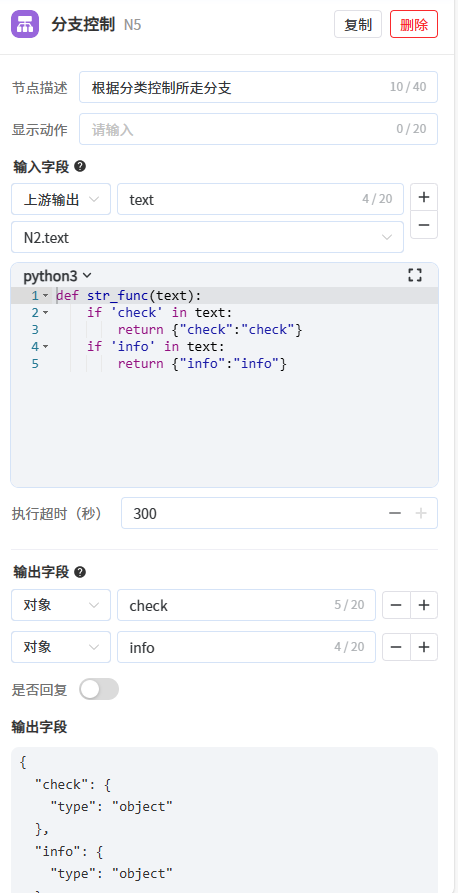
具体步骤:
- 修改输入参数为text,选择上游输出,值选择将用户问题归类的LLM节点的text输出参数
- 将以下代码粘贴到代码框中
python
def str_func(text):
if 'check' in text:
return {"check":"check"}
if 'info' in text:
return {"info":"info"}- 修改输出字段为check和info
- 第6步:新增LLM节点,用于合同审查。输入为合同文件的内容信息、用户指令,编写提示词使其发现并返回合同中的审查问题。开启是否回复,将输出显示给用户。
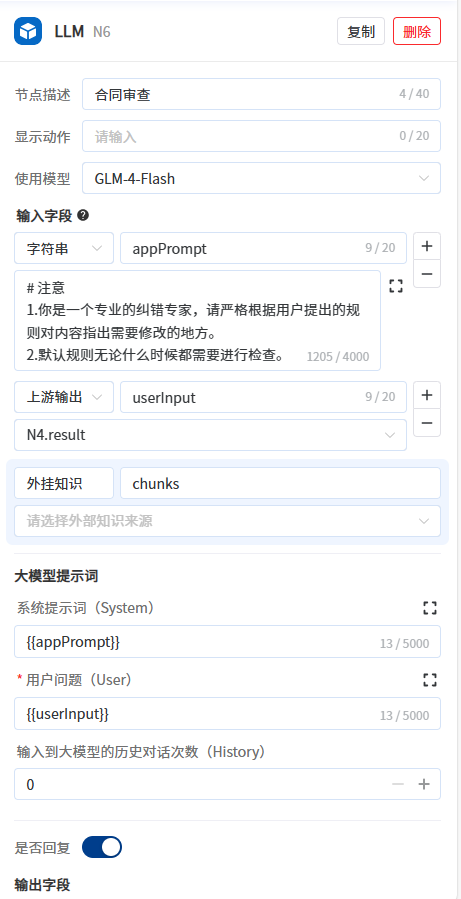
具体步骤:
- 修改输入字段appPrompt类型为字符串,将以下提示词粘贴到输入参数appPrompt值输入框中
text
# 注意
1.你是一个专业的纠错专家,请严格根据用户提出的规则对内容指出需要修改的地方。
2.默认规则无论什么时候都需要进行检查。
2.我不需要你对内容进行推断。
3.你需要对每一条规则都进行评审。
4.我不需要你对内容的格式以及规范上进行评审,请根据规则专注在内容上进行评审。
5.如果是无需修改的规则则不用返回。
6.如果判断出需要修改,但是文档内又没有这一类的信息,请不要胡编乱造。
# 审查规则,请无论什么情况都需要检查以下的规则并给出结论:
文本中出现的拼写错误、用词不当、多余的字或缺失的字等问题
句子结构不符合语法规则,导致意义模糊或难以理解
检查合同中的每一项信息项,如果有为空的情况需要提示,为空的情况就是如果是:后面没有内容并且进行换行,就代表为空
有金额的地方,必须有小写和大写,且数字必须相同
所有的“甲方”,其名称必须相同(如果"甲方"信息未填写,则不用判断)
所有的“乙方”,其名称必须相同(如果"乙方"信息未填写,则不用判断)
合同总价必须等于各分项价格之和
如果有手机或者手机号码等信息,检查是否为11位;(若检查出手机号信息位数不对,你只需要告诉我号码错误,多了还是少了,请不要自己补充胡编乱造)
## 账号信息检查
如果用户输入了有关甲方乙方的账号信息,请添加以下审查规则进行检查,如果没有则不用检查:
检查甲方开票信息是否正确;
判断合同中是否有收款账号信息,如果没有要求补充;
检查乙方账号信息是否正确;
## 在内容最后严格按照以下格式下一个结论,"需要修改为:"后面的内容需要进行加粗,注意不是全部加粗,而是在需要修改的内容上要加粗:
1.依据规则"xxx","xxx"需要修改为:xxx
判断原因:xxx
## 需要检查合同中的每一项信息项,如果有为空的情况需要提示
例如:
给出的审查内容是:甲方:\n法定代表人:\n地址:\n\n乙方:\n法定代表人:\n地址:\n\n鉴于:\n1、甲方拟为某客户(以下简称“客户”)开发、建设专利大模型系统\n2、甲方拟将该系统的部分工作委托给乙方开展\n3、客户要求甲方提前投入,并在2024年9月30日前上线该系统的临时版本(以下简称“临时系统”)
代表甲方,法定代表人,乙方,地址为空,你需要返回“依据规则"需要检查合同中的每一项信息项,如果有为空的情况需要提示",甲方,法定代表人,乙方,地址为空需要进行补充”
这里给出一个例子,按照这个格式回复,"需要修改为:"后面的内容需要进行加粗,注意不是全部加粗,而是在需要修改的内容上要加粗。
1.依据规则"所有的“甲方”,其名称必须相同","名称:广州华微明天软件技术有限公司"需要修改为:xxx
判断原因:xxx<br><br>
2.依据规则"检查乙方账号信息是否正确;","乙方收款账户信息的名称"需要修改为:xxx
判断原因:xxx<br><br>- 输入字段userInput的值选择获取文件全文信息的代码执行节点的输出字段result
- 第7步:新增LLM节点,用于合同信息提取。输入为合同文件的内容信息、用户指令,编写提示词使其提取合同文件中用户需要的信息。开启是否回复,将输出显示给用户。
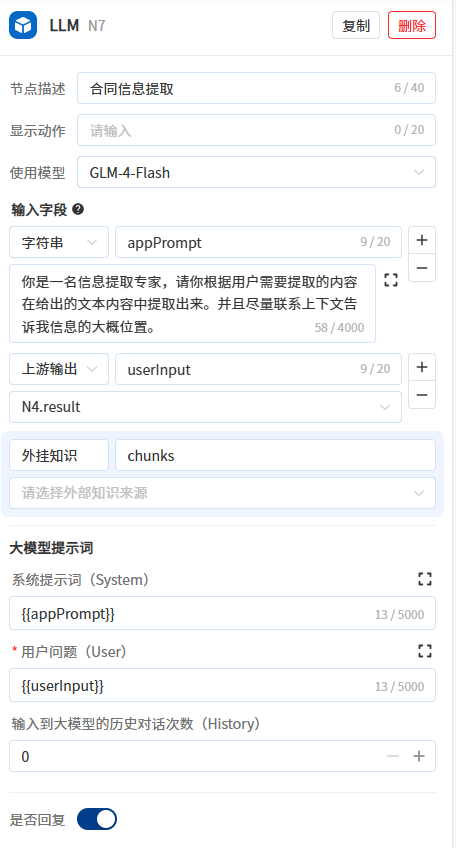
具体步骤:
- 修改输入字段appPrompt类型为字符串,将以下提示词粘贴到输入参数appPrompt值输入框中
text
你是一名信息提取专家,请你根据用户需要提取的内容在给出的文本内容中提取出来。并且尽量联系上下文告诉我信息的大概位置。- 输入字段userInput的值选择获取文件全文信息的代码执行节点输出字段result
建立工作流应用
第1步:AI平台—>我的应用—> 新增应用—>选择工作流应用类型,输入应用信息
第2步:选择目标工作流
第3步:勾选上传文件,配置上传文件的要求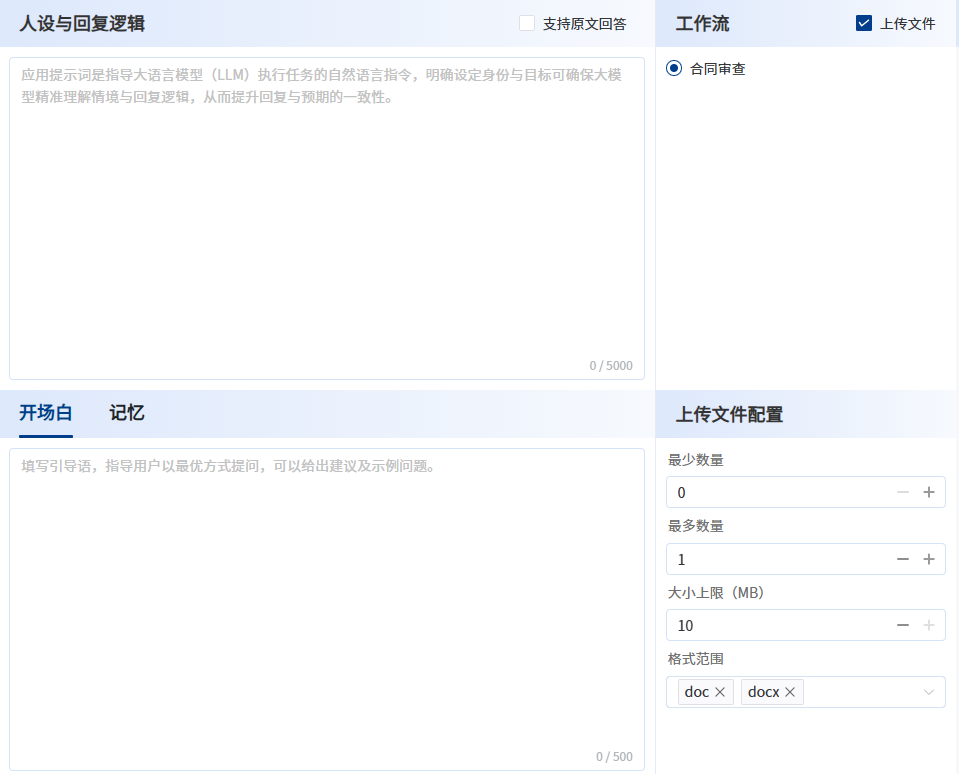
第4步:根据页面提示完成设置后发布应用